
如何估算 Token 数量:基于内容规模的快速估算法
介绍 LLM Token 估算的核心方法,从精确计算到基于内容规模的快速估算技巧,包括按字符数、语言类型、内容类型的经验公式和参考表,帮助你在调用 API 前快速预判成本。
概述
调用大模型 API 时,计费单元不是字符数,也不是单词数,而是 Token。Input Token 和 Output Token 的单价往往不同,且上下文窗口有硬上限。在正式发起请求前,快速估算 Token 数量,是控制成本、避免截断、选择合适模型的前提。
本文从「精确计算」讲到「基于内容规模的快速估算」,核心关注后者——如何在不加载 tokenizer 的情况下,通过文本的体量特征(字符数、词数、内容类型)给出一个足够接近的估计值。
一、Token 的本质
Token 是模型处理文本的最小单位。不同模型使用不同的分词器(Tokenizer),比如:
| 模型/系列 | 分词器 | 典型特点 |
|---|---|---|
| GPT-4 / GPT-4o | BPE (cl100k_base / o200k_base) |
英文高效,常见词一个 token |
| Claude 系列 | SentencePiece 改进版 | 与 GPT 接近但略有差异 |
| Llama 系列 | SentencePiece | 对代码和多语言支持较好 |
| DeepSeek 系列 | 自研 BPE | 中文优化,汉字压缩率更高 |
| Gemini 系列 | SentencePiece | Google 自研,与上述差异稍大 |
同一个字符串,在不同分词器下的 token 数可能相差 10%~30%。但在工程估算中,通常只需要一个「误差在 ±25% 以内」的近似值即可。
二、精确计算:什么时候必须用 Tokenizer
如果你需要精确值,必须使用对应模型的 tokenizer:
Python (OpenAI / 通用)
import tiktoken
enc = tiktoken.get_encoding("cl100k_base") # GPT-4, GPT-4o 等
tokens = enc.encode("Hello, 世界!")
print(len(tokens)) # 精确 token 数
JavaScript
import { encode } from 'gpt-tokenizer';
const tokens = encode("Hello, 世界!");
console.log(tokens.length);
在线工具
精确计算的代价是需要加载词表(通常 10MB~60MB),对于高频、低延迟或内存受限的场景并不合适。这时就需要基于规模的快速估算。
三、基于内容规模的快速估算方法
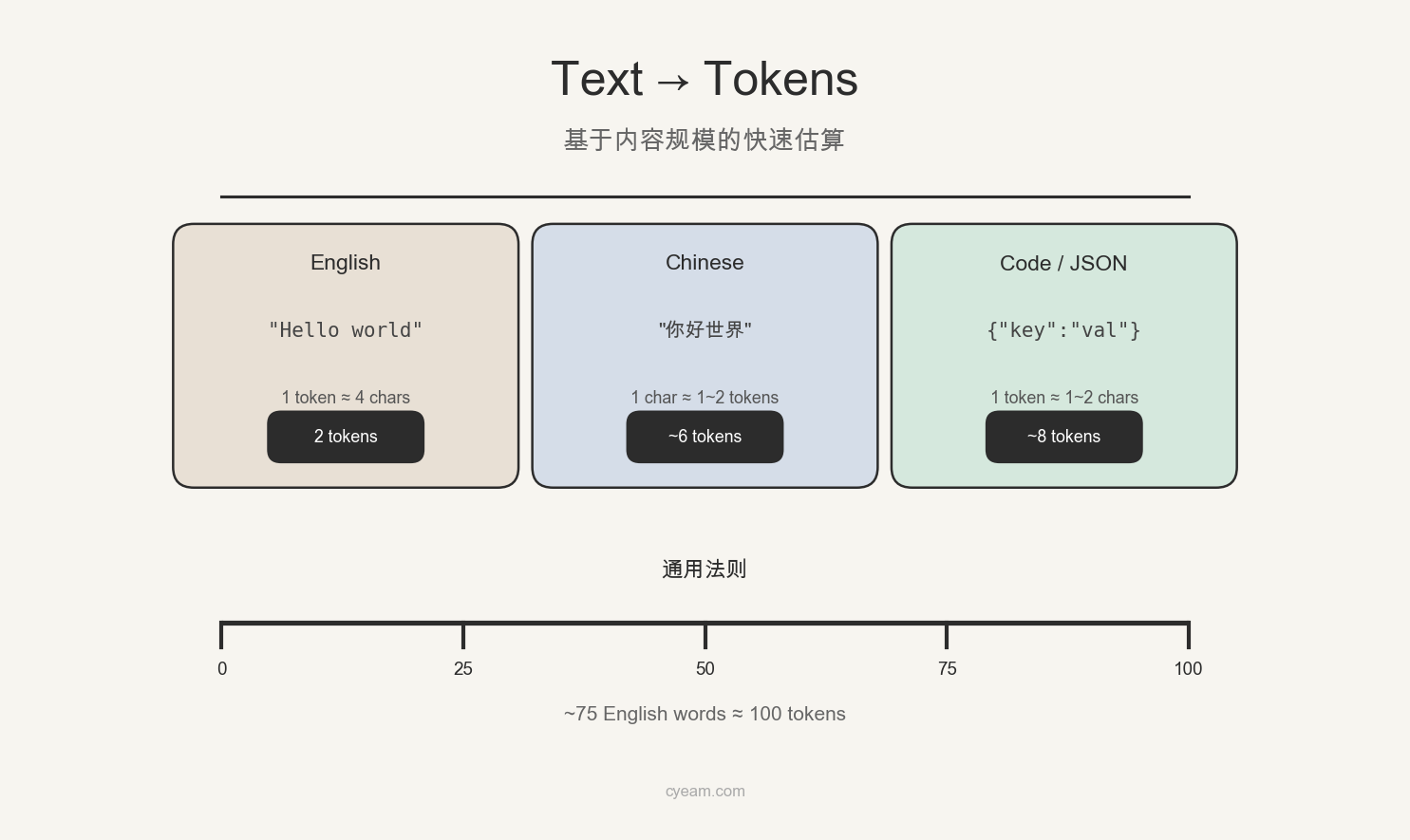
3.1 通用经验:字符数 ÷ 4
对于英文为主的文本,最粗糙也最实用的经验公式:
Token 数 ≈ 字符数 ÷ 4
这个公式的依据是:OpenAI 官方给出的经验值——1 token ≈ 4 个字符(英文)。它适用于:
- 快速心算
- 日志、文档的批量预估
- 客户端在调用 API 前做前驱校验
示例:一篇 8,000 字符的技术博客,估算约 2,000 tokens。
更精细的英文换算关系(OpenAI 官方参考):
| 指标 | 换算关系 |
|---|---|
| 字符 | 1 token ≈ 4 个字符 |
| 单词 | 1 token ≈ 0.75 个单词 |
| 句子 | 1~2 句话 ≈ 30 tokens |
| 段落 | 1 个段落 ≈ 100 tokens |
| 长文 | ~1,500 词 ≈ 2,048 tokens |
3.2 按语言类型区分
不同语言的 token 密度差异很大,而且不同模型对同一语言的压缩率也不同:
| 语言 | GPT/Claude 估算 | DeepSeek 等中文优化模型 | 说明 |
|---|---|---|---|
| 英文 | 1 token ≈ 4 字符 / 0.75 单词 | 相近 | 分词效率最高 |
| 中文 | 1 字 ≈ 1~2 tokens | 1 字 ≈ 0.5~0.7 token | 模型差异极大 |
| 日文/韩文 | 1 字 ≈ 1~2 tokens | 相近 | 与中文在 GPT 中表现类似 |
| 代码(Python/Go) | 1 token ≈ 3~4 字符 | 相近 | 关键字和缩进会被压缩 |
| 代码(JSON/XML) | 1 token ≈ 1~2 字符 | 相近 | 大量标点符号,密度很低 |
关键区别:GPT-4/Claude 的 cl100k_base 词表对 CJK(中日韩)字符覆盖有限,一个汉字常被拆成 2~3 个 token(例如 "猫" 在 cl100k_base 中是 3 个 token)。而 DeepSeek 等模型在训练 tokenizer 时刻意提升了中文覆盖率,因此 1 个汉字通常只需约 0.6 个 token。
混合文本的通用公式(针对 GPT/Claude):
Token 数 ≈ 中文字符数 × 1.5 + 英文单词数 × 1.3 + 其他符号 × 0.5
3.3 按内容类型估算
在工程实践中,更实用的方式是按内容类型直接查表估算。先定义内容规模档位,再匹配经验区间:
| 内容类型 | 典型规模 | 估算 Token 数 | 适用场景 |
|---|---|---|---|
| 一句话查询 | 5~20 个词 | 10~30 | 单轮对话、指令 |
| 一段 UI 提示词 | 50~100 词 | 80~150 | 系统 Prompt、按钮文案 |
| 一封邮件 | 200~500 词 | 300~700 | 邮件摘要、自动回复 |
| 一篇博客文章 | 1,000~2,000 词 | 1,500~3,000 | 内容生成、SEO 分析 |
| 技术文档/报告 | 3,000~8,000 词 | 5,000~12,000 | 文档问答、知识库 |
| 研究论文 | 5,000~10,000 词 | 8,000~15,000 | 论文摘要、翻译 |
| 长篇小说章节 | 20,000~50,000 词 | 30,000~80,000 | 长文分析、续写 |
| 整本书(200页) | ~60,000 词 | ~100,000 | 全书摘要、角色分析 |
用法:先判断你的输入属于哪一档,再取区间中值作为预算,最后留 20% 余量给 Output Token。
3.4 考虑 Output Token
Input 只是成本的一半。估算总成本时,别忘了输出:
总 Token 数 = Input Token + Output Token
Output Token 的预估取决于任务类型:
| 任务类型 | Output / Input 比例 | 示例 |
|---|---|---|
| 分类/判断 | 1:50 ~ 1:100 | “是/否”、标签 |
| 摘要 | 1:5 ~ 1:10 | 长文压缩 |
| 翻译 | 1:1 ~ 1:2 | 中英互译 |
| 问答 | 1:2 ~ 1:5 | 知识库问答 |
| 生成/创作 | 1:1 ~ 2:1 | 写代码、写文章 |
经验法则:Output Token 按 Input 的 30%~50% 预算是比较安全的起点。注意 Output Token 的单价通常是 Input 的 2~4 倍。
四、实用代码:一个通用的估算函数
如果你不想引入 tiktoken,可以用这个轻量级估算函数覆盖绝大多数场景(主要针对 GPT/Claude 系列):
import re
def estimate_tokens(text: str) -> int:
"""
轻量级 Token 估算函数(针对 GPT/Claude 系列)。
对中文和英文混合文本有较好近似度,误差通常在 ±25% 以内。
"""
# 中文字符:在 cl100k_base 中通常 1 字 ≈ 1.5 token
chinese_chars = len(re.findall(r'[\u4e00-\u9fff]', text))
# 移除中文后的文本,按英文词估算
non_chinese = re.sub(r'[\u4e00-\u9fff]', ' ', text)
english_words = len(re.findall(r"[a-zA-Z0-9_]+(?:[-'][a-zA-Z0-9_]+)*", non_chinese))
# 其他符号(标点、空格等)额外估算
other_symbols = len(re.findall(r'[^\w\s\u4e00-\u9fff]', text))
total = int(chinese_chars * 1.5 + english_words * 1.3 + other_symbols * 0.5)
return max(1, total)
# 示例
samples = [
"Hello world",
"你好,世界",
"Hello 世界,this is a test 测试一下。",
"The quick brown fox jumps over the lazy dog.",
]
for s in samples:
print(f"'{s[:30]}...' -> ~{estimate_tokens(s)} tokens")
输出参考:
'Hello world...' -> ~2 tokens
'你好,世界...' -> ~6 tokens
'Hello 世界,this is a test ...' -> ~16 tokens
'The quick brown fox jumps o...' -> ~9 tokens
五、实战:一次完整的成本预估
假设你要做一个「论文阅读助手」,每次用户上传一篇 PDF 论文(约 8,000 英文词),系统需要:
- 输入:论文全文 + 系统 Prompt(约 500 词)
- 输出:结构化摘要 + 关键结论(约 1,500 词)
估算过程:
论文 Token: 8,000 词 × 1.3 = 10,400
系统 Prompt: 500 词 × 1.3 = 650
Input 合计: 11,050
Output 预估: 1,500 词 × 1.3 = 1,950
总 Token 数: 13,000(约)
成本估算(以 GPT-4o 为例,$2.50 / 1M input, $10.00 / 1M output):
Input 成本: 11,050 × $2.50 / 1M = $0.0276
Output 成本: 1,950 × $10.00 / 1M = $0.0195
单次总成本: ~$0.047
如果每天有 1,000 次调用:月成本 ≈ $1,410。在立项前就能给出这个数,是 Token 估算的核心价值。
六、常见误区
| 误区 | 正确理解 |
|---|---|
| “1 个词 = 1 个 token” | 仅对英文简单词成立;unbelievable 会被拆成 un + believ + able |
| “1 个汉字 = 1 个 token” | GPT/Claude 中通常 1~2 个 token;DeepSeek 中约 0.6 个 token |
| “标点符号不算 token” | 标点通常是独立 token,JSON 中的 { } 密度极高 |
| “System Prompt 不计费” | 所有输入都计费,包括 system、history、function 定义 |
| “只需要算 Input” | Output 往往单价更高(2~4x),且长输出会快速累积 |
七、总结
| 方法 | 精度 | 适用场景 | 代价 |
|---|---|---|---|
| 精确 Tokenizer | 100% | 计费对账、精确控制 | 加载词表、有依赖 |
| 字符数 ÷ 4 | ±25% | 英文文本快速心算 | 无 |
| 语言混合公式 | ±25% | 中英混合工程代码 | 无 |
| 内容类型查表 | ±30% | 立项评估、架构设计 | 无 |
Token 估算不是数学题,而是工程预算题。在 90% 的场景下,基于内容规模的快速估算足够让你做出正确的模型选择和成本控制决策。剩下 10% 需要精确值的场景,再请出 tiktoken 也不迟。
原文链接: 如何估算 Token 数量:基于内容规模的快速估算法 ,转载请注明来源!
– EOF –