
Cyeam AI 架构问答的三档变速
详细介绍Cyeam AI架构问答系统的三种模式:Fast模式(向量搜索快速回答)、Think模式(动态Prompt选择+MCP Wiki/Skill工具调用+SSE实时思考流)和Expert模式(双路交叉验证深度分析)。文章涵盖整体链路设计、代码实现、MCP集成架构和安全设计,为开发者提供构建多模式AI问答系统的完整参考。
最近把 Cyeam 的 AI 问答接口 /ai/architecture 做了一次大升级,引入了 MCP(Model Context Protocol)和动态 Prompt 选择机制。现在的接口支持三种模式:fast、think、expert,分别对应不同的信息检索策略和回答深度。
整体链路
用户提问 → 模式选择 → 信息检索 → LLM 生成 → SSE 流式返回
三种模式共用同一个 SSE 接口,前端通过 mode 参数切换。后端使用 langchaingo 对接 SiliconFlow 的 LLM,所有结果通过 SSE 实时推送到前端。
Fast 模式:快就一个字
Fast 模式只干一件事:向量搜索 + 直接回答。
用户提问 → Qdrant 向量搜索(Top2) → LLM 总结回答
代码很直接:
func architectureFast(c *app.Context, q string) error {
se := search.QdrantSearch(q, 1, 2, "", true)
messages := []llms.MessageContent{
llms.TextParts(llms.ChatMessageTypeSystem, architecturePrompt),
llms.TextParts(llms.ChatMessageTypeHuman,
fmt.Sprintf(`问题:%s。参考资料:%s。`, q, util.JsonSlient(se))),
}
return streamResponse(c, aiagent.GetLLM("SiliconFlow"), messages)
}
不做 MCP Wiki 查询,不展示思考过程。适合已经有明确答案的问题,3-10 秒出结果。
Think 模式:最复杂的那个
Think 模式的核心是动态决策——先让 LLM 判断问题类型,再选择处理路径。
用户提问 → 动态选择 Prompt → 分支处理
↓
┌────────┴────────┐
↓ ↓
普通 Prompt Skill Prompt
(wiki_query) (skill_weather)
↓ ↓
MCP Wiki 查询 读取 Skill Resources
↓ ↓
LLM 生成回答 LLM 生成 URL → curl 工具
↓
实时数据 → 最终回答
动态 Prompt 选择
系统启动时从 MCP 服务器拉取所有可用 Prompts 并缓存。收到问题时,用一个独立的 LLM 调用做”提示词路由”:
func selectDynamicPrompt(ctx, c, q) (string, string, error) {
prompts := aiagent.ListPrompts() // 从 MCP 缓存读取
// 让 LLM 选择最合适的 prompt
messages := []llms.MessageContent{
llms.TextParts(llms.ChatMessageTypeSystem, "你是指令选择助手..."),
llms.TextParts(llms.ChatMessageTypeHuman,
fmt.Sprintf("可用提示词:...\n用户问题: %s\n请只返回名称", q)),
}
resp, _ := llm.GenerateContent(ctx, messages)
selectedName := strings.TrimSpace(resp.Choices[0].Content)
// 获取选中的 prompt 内容
promptMessages, _ := aiagent.GetPrompt(ctx, selectedName, nil)
return promptContent, selectedName, nil
}
分支处理
路径 A:普通 Prompt
如果选中的是 wiki_query_system,走传统的 Wiki 查询流程:
- 扫描 MCP Tools,找到
wiki_query、wiki_search_index等 Wiki 相关工具 - 依次调用,参数为用户提问
- 如果返回了文章名,再调用
wiki_get_article获取完整内容 - 所有结果拼接成参考资料,传给 LLM 生成回答
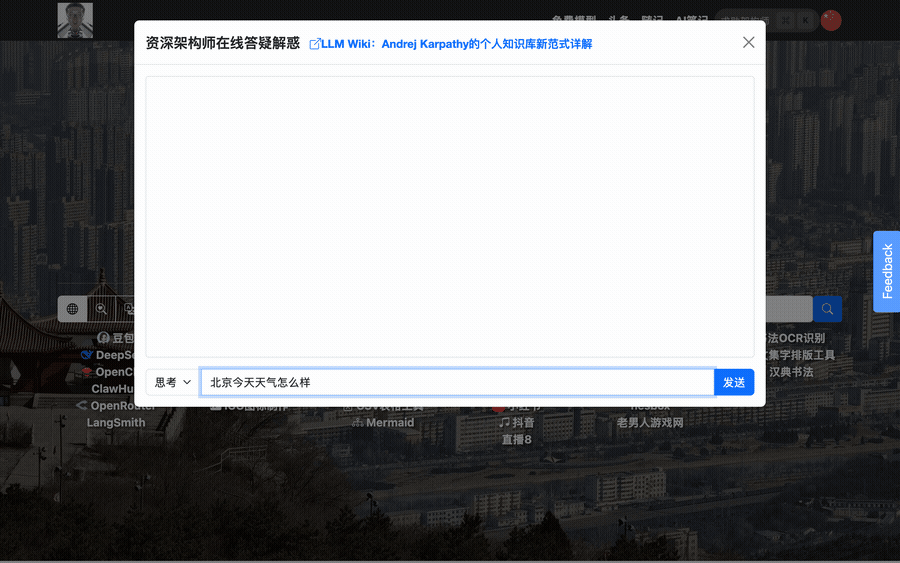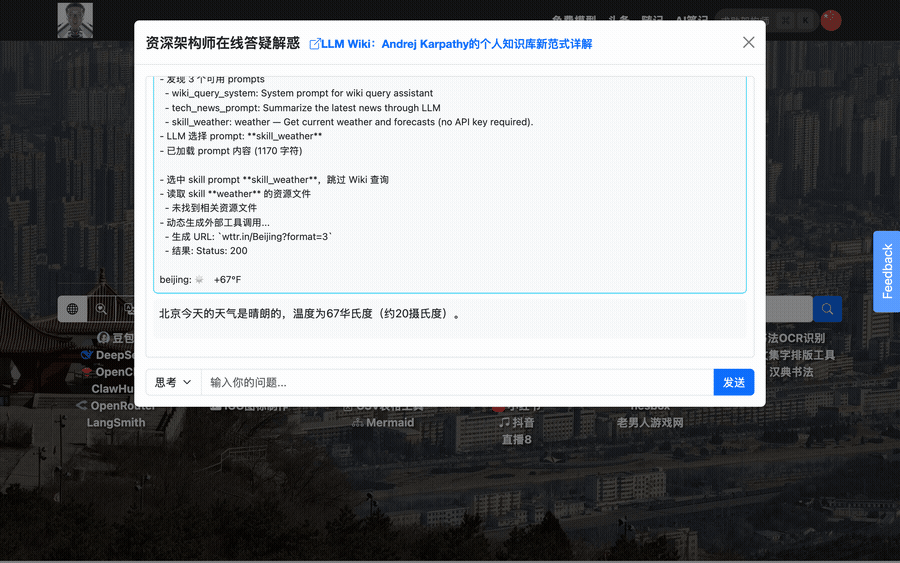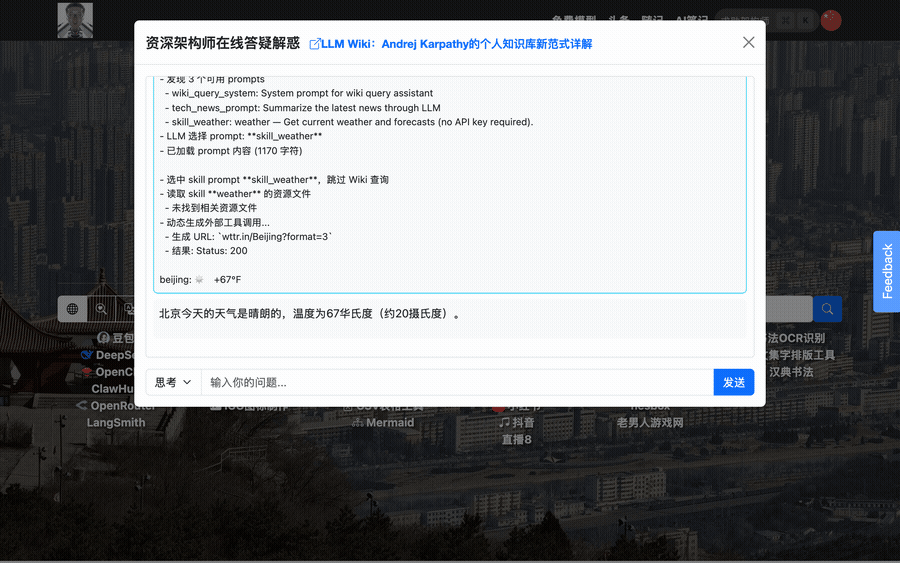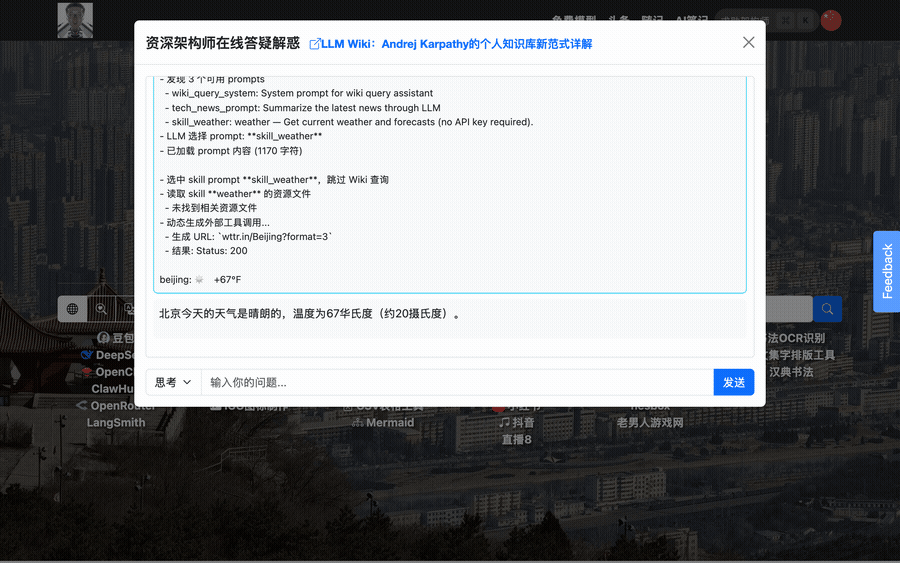
整个过程中,thinking 内容通过 SSE 实时发送,用户能看到调用了哪些工具、结果摘要是什么。
路径 B:Skill Prompt
如果选中的是 skill_weather,走 Skill 处理流程:
- 跳过 Wiki 查询
- 读取 Skill Resources:扫描 MCP Resources,找到
skill://weather/前缀的资源 - 动态工具调用:
- LLM 根据用户问题生成 URL(如
wttr.in/Beijing?format=3) - 调用 MCP
curl工具执行 HTTP 请求 - 将实时数据追加到对话上下文
- LLM 根据用户问题生成 URL(如
- 最终生成:LLM 基于 Skill Prompt + 实时数据回答
func executeDynamicTool(ctx, llm, q, skillContext) (string, bool) {
// 发现可用的执行工具
execTools := filter(mcpTools, t => t.Name == "curl" || isSkillExec(t.Name))
// 让 LLM 生成 URL
messages := []llms.MessageContent{
llms.TextParts(llms.ChatMessageTypeSystem, "URL 生成助手..."),
llms.TextParts(llms.ChatMessageTypeHuman,
fmt.Sprintf("用户问题:%s\n请生成 URL 路径", q)),
}
resp, _ := llm.GenerateContent(ctx, messages)
url := extractFirstURL(resp.Choices[0].Content)
// 调用 MCP curl 工具
args := map[string]any{"url": url}
callResp, _ := aiagent.CallTool(ctx, "curl", args)
return toolResult, true
}
零硬编码 Skill
新增 Skill 只需在 MCP 服务端添加目录:
skills/
weather-1.0.0/
_meta.json # slug、name 等元数据
SKILL.md # Skill 教程 + 白名单 URL
MCP 服务端启动时自动:
- 从
SKILL.md提取白名单 URL - 暴露 Prompt
skill_{slug} - 暴露 Tool
skill_{slug}_exec - 暴露 Resources
skill://{slug}/...
Web 端零改动自动适配。
Expert 模式:双路交叉验证
Expert 模式同时使用向量搜索和Wiki MCP两路信息源:
用户提问 → Qdrant 向量搜索(Top3) → 阶段一展示
→ MCP Wiki 工具查询 → 阶段二展示
→ 两路资料合并 → LLM 深度分析
两路资料合并后传给 LLM,要求从多个维度分析(技术选型、性能、可扩展性、维护成本、安全),给出具体方案、代码示例、对比和推荐意见。
messages := []llms.MessageContent{
llms.TextParts(llms.ChatMessageTypeSystem, expertPrompt),
llms.TextParts(llms.ChatMessageTypeHuman, fmt.Sprintf(`问题:%s。
## 向量搜索资料
%s
## Wiki 参考资料
%s`, q, util.JsonSlient(se), wikiResult)),
}
SSE 流式输出
三种模式都通过 SSE 推送,数据结构统一:
interface StreamResponse {
thinking?: string; // 思考过程
content?: string; // 回答片段
done?: boolean; // 结束标记
}
data: {"thinking":"## 阶段一:动态选择 Prompt\n- 发现 4 个可用 prompts..."}
data: {"content":"北京今天的天气是"}
data: {"content":"晴朗的"}
data: {"done":true}
Thinking 内容在 Think 和 Expert 模式下才有:
- Think:Prompt 选择过程、Wiki 工具调用、Skill 工具调用
- Expert:阶段一(向量搜索)+ 阶段二(Wiki MCP 查询)
三种模式对比
| 维度 | Fast | Think | Expert |
|---|---|---|---|
| 信息源 | Qdrant Top2 | Qdrant / Wiki / Skill | Qdrant Top3 + Wiki |
| Thinking | 无 | 有 | 有(两阶段) |
| 实时数据 | 不支持 | 支持(Skill 工具) | 支持(Skill 工具) |
| 回答深度 | 总结归纳 | 自适应 | 多维度深度分析 |
| 典型耗时 | 3-10s | 10-60s | 30-120s |
MCP 集成架构
┌─────────────────┐
│ cyeam_web │ ← Go + langchaingo
│ │
│ /ai/architecture │
│ fast/think/expert │
└────────┬────────┘
│ HTTPS (StreamableHTTP)
▼
┌─────────────────┐
│ cyeam-wiki-mcp │ ← Node.js + MCP SDK
│ │
│ • Tools │ wiki_query, wiki_get_article,
│ │ wiki_search_index, wiki_get_graph,
│ │ tech_news, curl, skill_xxx_exec
│ • Resources │ wiki://index, skill://{slug}/...
│ • Prompts │ wiki_query_system, skill_xxx
└─────────────────┘
StreamableHTTP 是 MCP 1.0 新增的传输协议,比 SSE 更轻量,支持无状态请求。服务端用 @modelcontextprotocol/sdk/server/streamableHttp.js 实现,客户端用 github.com/mark3labs/mcp-go/client/transport 的 NewStreamableHTTP。
安全设计
- URL 白名单:MCP 服务端
curl工具只允许访问 Skill 白名单中的 URL - 协议剥离:LLM 可能生成带
https://的 URL,Web 端自动剥离后传给 MCP - 命令注入防护:
skill_xxx_exec禁止包含;|&$\n` 等特殊字符的命令 - 失败隔离:MCP 连接失败、工具调用失败都不影响 Web 端核心功能
这次改造最大的收获是让系统具备了动态适配能力——新增 Skill 不需要改 Web 端代码,MCP 协议的标准化接口让 AI 工具的生态扩展变得简单。接下来打算把更多日常开发工具(代码格式化、API 测试、文档生成)都做成 Skill,让 Cyeam 真正成为开发者的 AI 助手。
原文链接: Cyeam AI 架构问答的三档变速 ,转载请注明来源!
– EOF –