
布隆过滤器
曾经听一位大神提起过布隆过滤器,一般用来过滤黑名单。之前去搜狗面试,最后一个题也是这个。当时果断没想起来。
这篇文章可能涉及到一些拓扑知识,可以参考之前的文章:
布隆过滤器的原理不算复杂。对数据进行查找,简单点的可以直接遍历;对于拍好顺序的数据,可以使用二分查找等。但这些方法的时间复杂度都较高,分别是O(n)和O(logn)。无法对大量乱序的数据进行快速的查找。
哈希,将给定的数据通过哈希函数得到一个唯一的值,此值可以作为数据的唯一标识,只要通过该标识,再通过哈希函数逆向计算,就能还原出来原始的数据。在前面的网址压缩的调研分析里面介绍的压缩网址的方法,其实也就是一种哈希,只不过借助了数据库的支持。
布隆过滤器就是借助了哈希实现的过滤算法。通过将黑名单的数据哈希之后,可以得到一个数据。申请一个数组空间,长度是黑名单的长度。将前面的数据转换成数组中唯一的一个单元,并且标记为1,标识此位置对应的数据是黑名单。如此一来,过滤的时候,将数据哈希之后,去前面的数组当中查找,如果对应的位置值为1,表明需要被过滤,如果是0,则不需要。如果黑名单有一亿个黑名单数据,每个数据需要1bit来记录,最后也就会占用1G空间,放在内存里面妥妥的。而哈希函数计算时间可以认为是O(1),所以过滤算法效率也很高。
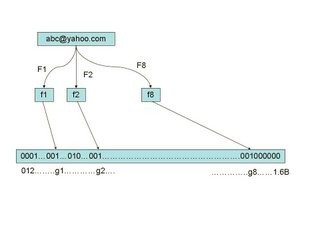
然而,哈希算法不可能保证不发生碰撞。尤其是黑名单这种字符串,可能会包含各种字符,也不能单纯的当作数字来处理。布隆过滤器的做法就是通过调用多个哈希函数,降低碰撞的概率。比如有3个哈希函数,碰撞概率都是10%,并且哈希方式不同,那么一个数据通过三次哈希得到的碰撞概率是单独哈希一次的 10%×10%×10%/10%=1%,也就是说,原本哈希一次碰撞概率为10%,现在三次是0.1%。黑名单误过滤的概率大大降低,而存在于黑名单当中的肯定会被过滤掉。而三次哈希的结果也直接放进之前的数组里即可。判断是否在黑名单当中,三次结果计算结果都匹配才需要过滤。
上面提到的需要用三个哈希函数只是举例子,数目没有限制。而哈希函数的选取,也会是一个问题。这些明天再说吧。
参考文献
原文链接: 布隆过滤器 ,转载请注明来源!
– EOF –